
Какую работу выполняют работы поисковых машин. Поисковые машины, поисковики и роботы-пауки. Будущее поисковиков. Кто такие поисковые роботы
Его работа заключается в тщательном анализе содержимого страниц представленных в Интернете сайтов и отправке результатов анализа в поисковой системы.
Новые страницы поисковый робот некоторое время обходит, но в дальнейшем они индексируются и при отсутствии каких-либо санкций со стороны поисковых систем могут отображаться в результатах поиска.
Принцип действия
Действие поисковых роботов основано на том же принципе, что и работа обыкновенного браузера. Посещая тот или иной сайт, они обходят часть его страниц или все страницы без исключения. Полученную информацию о сайте они отправляют в поисковый индекс. Эта информация появляется в поисковой выдаче, соответствующей тому или иному запросу.
Из-за того, что поисковые роботы могут посещать только часть страниц, с индексацией больших сайтов могут возникать проблемы. Такие же точно проблемы могут возникать из-за низкого качества .
Перебои в его работе делают часть страниц недоступными для анализа. Важную роль в оценке сайта поисковыми роботами играет правильно составленная и грамотно настроенный файл robots.txt.
Глубина сканирования ресурса и периодичность обхода сайтов поисковыми роботами зависит от:
- Алгоритмов работы поисковых систем.
- Частоты обновления сайтов.
- Структуры сайтов.
Поисковый индекс
База данных с информацией, которую собирают поисковые роботы, называется поисковым индексом. Эта база используется поисковыми системами для формирования результатов выдачи по конкретным .
В индекс заносится не только информация о сайтах: поисковые роботы способны распознавать изображения, мультимедиа файлы и документы в различных электронных форматах (.docx, .pdf и др).
Один из самых активных поисковых роботов системы Яндекс – быстробот. Он постоянно сканирует новостные ресурсы и другие часто обновляемые сайты. , который не замечен быстроботом, не имеет смысла.
Привлечь его можно с помощью специальных инструментов, причем действенны они для сайтов самого разного назначения. Для проверки сайтов на доступность, для анализа отдельных их характеристик, для индексации картинок и документов в поисковых системах есть отдельные роботы.
- Определения и терминология
- Имена роботов
- Немного истории
- Что делают роботы поисковых систем
- Поведение роботов на сайте
- Управление роботами
- Выводы
Что такое роботы поисковых систем? Какую функцию они выпол няют? Каковы особенности работы поисковых роботов? Здесь мы постараемся дать ответ на эти и некоторые другие вопросы, свя занные с работой роботов.
Определения и терминология
В английском языке существует несколько вариантов названий поисковых роботов: robots, web bots, crawlers, spiders; в русском языке фактически прижился один термин - роботы, или сокращенно - боты.
На сайте www. robotstxt. org дается следующее определение роботам:
“Веб-робот - это программа, которая обходит гипертекстовую структуру WWW, рекурсивно запрашивая и извлекая документы”.
Ключевое слово в этом определении - рекурсивно, т.е. имеется в виду, что после получения документа робот будет запрашивать документы по ссылкам из него и т.д.
Имена роботов
Большинство поисковых роботов имеют свое уникальное имя (кроме тех роботов, которые по каким-то причинам маскируются под пользовательские браузеры).
Имя робота можно увидеть в поле User-agent серверных лог-файлов, отчетах систем серверных статистик, а также на страницах помощи поисковых систем.
Так, робота Яндекса собирательно называют Yandex, робота Рамблера - StackRambler, робота Yahoo! - Slurp и т.д. Даже пользовательские программы, собирающие контент для последующего просмотра, могут специальным образом представляться с помощью информации в поле User-agent.
Кроме имени робота, в поле User-agent может находиться больше информации: версия робота, предназначение и адрес страницы с дополнительной информацией.
Немного истории
Еще в первой половине 1990-х годов, в период развития Интернета, существовала проблема веб-роботов, связанная с тем, что некоторые из первых роботов могли существенно загрузить веб-сервер, вплоть до его отказа, из-за того, что делали большое количество запросов к сайту за слишком короткое время. Системные администраторы и администраторы веб-серверов не имели возможности управлять поведением робота в пределах своих сайтов, а могли лишь полностью закрыть доступ роботу не только к сайту, а и к серверу.
В 1994 году был разработан протокол robots.txt, задающий исключения для роботов и позволяющий пользователям управлять поисковыми роботами в пределах своих сайтов. Об этих возможностях вы читали в главе 6 “Как сделать сайт доступным для поисковых систем”.
В дальнейшем, по мере роста Сети, количество поисковых роботов увеличивалось, а функциональность их постоянно расширялась. Некоторые поисковые роботы не дожили до наших дней, оставшись только в архивах серверных лог-файлов конца 1990-х. Кто сейчас вспоминает робота T-Rex, собирающего информацию для системы Lycos? Вымер, как динозавр, по имени которого назван. Или где можно найти Scooter - робот системы Altavista? Нигде! А ведь в 2002 году он еще активно индексировал документы.
Даже в имени основного робота Яндекса можно найти эхо минувших дней: фрагмент его полного имени “compatible; Win16;” был добавлен для совместимости с некоторыми старыми веб-серверами.
Что делают роботы поисковых систем
Какие же функции могут выполнять роботы?
В поисковой машине функционирует несколько разных роботов, и у каждого свое предназначение. Перечислим некоторые из задач, выполняемых роботами:
- обработка запросов и извлечение документов;
- проверка ссылок;
- мониторинг обновлений;проверка доступности сайта или сервера;
- анализ контента страниц для последующего размещения контекстнойрекламы;
- сбор контента в альтернативных форматах (графика, данные в форматахRSSnAtom).
В качестве примера приведем список роботов Яндекса. Яндекс использует несколько видов роботов с разными функциями. Идентифицировать их можно по строке User-agent.
- Yandex/1.01.001 (compatible; Win 16; I) -основной индексирующий робот.
- Yandex/1.01.001 (compatible; Win 16; P) -индексатор картинок.
- Yandex/1.01.001 (compatible; Win 16; H) -робот, определяющийзеркала сайтов.
- Yandex/1.03.003 (compatible; Win 16; D) -робот, обращающийсяк странице при добавлении ее через форму “Добавить URL”.
- Yandex/1.03.000 (compatible; Win 16; М) - робот, обращающийсяпри открытии страницы по ссылке “Найденные слова”.
- YandexBlog/0.99.101 (compatible; DOS3.30; Mozilla/5.0; В;robot) - робот, индексирующий xml-файлы для поиска по блогам.
- YandexSomething/1.0 - робот, индексирующий новостные потоки партнеров Яндекс.Новостей и файлы robots. txt для робота поиска по блогам.
Кроме того, в Яндексе работает несколько проверяющих роботов - “просту- кивалок”, которые только проверяют доступность документов, но не индексируют их.
- Yandex/2.01.000 (compatible; Win 16; Dyatel; С) - “просту-кивалка” Яндекс.Каталога. Если сайт недоступен в течение несколькихдней, он снимается с публикации. Как только сайт начинает отвечать, онавтоматически появляется в каталоге.
- Yandex/2.01.000 (compatible; Win 16; Dyatel; Z) - “просту-кивалка” Яндекс.Закладок. Ссылки на недоступные сайты выделяютсясерым цветом.
- Yandex/2.01.000 (compatible; Win 16; Dyatel; D) -”простуки-валка” Яндекс.Директа. Она проверяет корректность ссылок из объявлений перед модерацией.
И все-таки наиболее распространенные роботы - это те, которые запрашивают, получают и архивируют документы для последующей обработки другими механизмами поисковой системы. Здесь уместно будет отделить робота от индексатора.
Поисковый робот обходит сайты и получает документы в соответствии со своим внутренним списком адресов. В некоторых случаях робот может выполнять базовый анализ документов для пополнения списка адресов. Дальнейшей обработкой документов и построением индекса поисковой системы занимается уже индексатор поисковой машины. Робот в этой схеме является всего лишь “курьером” по сбору данных.
Поведение роботов на сайте
Чем отличается поведение робота на сайте от поведения обычного пользователя?
- Управляемость. Прежде всего “интеллигентный” робот должен запросить с сервера файл robots . txt с инструкциями по индексации.
- Выборочное выкачивание. При запросе документа робот четко указываеттипы запрашиваемых данных, в отличие от обычного браузера, готового принимать все подряд. Основные роботы популярных поисковиков в первую очередь будут запрашивать гипертекстовые и обычные текстовые документы, оставляя без внимания файлы стилен оформления CSS, изображения, видео. Zip-архивы и т.п. В настоящее время также востребована информация в форматах PDF, Rich Text, MS Word, MS Excel и некоторых других.
- Непредсказуемость. Невозможно отследить или предсказать путь роботано сайту, поскольку он не оставляет информации в поле Referer - адресстраницы, откуда он пришел; робот просто запрашивает список документов, казалось бы, в случайном порядке, а на самом деле в соответствии сосвоим внутренним списком или очередью индексации.
- Скорость. Небольшое время между запросами разных документов. Здесьречь идет о секундах или долях секунды между запросами двух разныхдокументов. Для некоторых роботов есть даже специальные инструкции,которые указываются в файле robots . txt, по ограничению скорости запроса документов, чтобы не перегрузить сайт.
Как может выглядеть HTML-страница в глазах робота, мы не знаем, но можем попытаться себе это представить, отключая в браузере отображение графики и стилевого оформления.
Таким образом, можно сделать вывод, что поисковые роботы закачивают в свой индекс HTML-структуру страницы, но без элементов оформления и без картинок.
Управление роботами
Как же вебмастер может управлять поведением поисковых роботов на своем сайте?
Как уже было сказано выше, в 1994 году в результате открытых дебатов вебмастеров был разработан специальный протокол исключений для роботов. До настоящего времени этот протокол так и не стал стандартом, который обязаны соблюдать все без исключения роботы, оставшись лишь в статусе строгих рекомендаций. Не существует инстанции, куда можно пожаловаться на робота, не соблюдающего правила исключений, можно лишь запретить доступ к сайту уже с помощью настроек веб-сервера или сетевых интерфейсов для IP-адресов, с которых “неинтеллигентный” робот отсылал свои запросы.
Однако роботы крупных поисковых систем соблюдают правила исключений, более того, вносят в них свои расширения.
Об инструкциях специального файла robots.txt. и о специальном мета-теге robots подробно рассказывалось в главе 6 “Как сделать сайт доступным для поисковых систем”.
С помощью дополнительных инструкций в robots.txt, которых нет в стандарте, некоторые поисковые системы позволяют более гибко управлять поведением своих роботов. Так, с помощью инструкции Crawl-delaу вебмастер может устанавливать временной промежуток между последовательными запросами двух документов для роботов Yahoo! и MSN, а с помощью инструкции Но-; t указать адрес основного зеркала сайта для Яндекса. Однако работать с нестандартными инструкциями в robots . txi следует очень осторожно, поскольку робот другой поисковой системы может проигнорировать не только непонятную ему инструкцию, но и весь набор правил, связанных с ней.
Управлять посещениями поисковых роботов можно и косвенно, например, робот поисковой системы Google чаще будет повторно забирать те документы, на которые много ссылаются с других сайтов.
Роботы-пауки у поисковых машин - это интернет-боты, в задачу которых входит систематический просмотр страниц в World Wide Web для обеспечения веб-индексации. Традиционно сканирование WWW-пространства осуществляется для того, чтобы обновить информацию о размещенном в сети контенте с целью предоставления пользователям актуальных данных о содержимом того или иного ресурса. О типах поисковых роботов и их особенностях и будет идти речь в данной статье.
Поисковые пауки могут именоваться еще и по-другому: роботы, веб-пауки, краулеры. Однако независимо от названия, все они заняты постоянным и непрерывным изучением содержимого виртуального пространства. Робот сохраняет список URL-адресов, документы по которым загружаются на регулярной основе. Если в процессе индексации паук находит новую ссылку, она добавляется в этот список.
Таким образом, действия краулера можно сравнить с обычным человеком за браузером. С тем лишь отличием, что мы открываем только интересные нам ссылки, а робот - все, о которых имеет информацию. Кроме того, робот, ознакомившись с содержимым проиндексированной страницы, передает данные о ней в специальном виде на сервера поисковой машины для хранения до момента запроса со стороны пользователя.
При этом каждый робот выполняет свою определенную задачу: какие-то индексируют текстовое содержимое, какие-то - графику, а третьи сохраняют контент в архиве и т.д.
Главная задача поисковых систем - создание алгоритма, который позволит получать информацию о быстро и наиболее полно, ведь даже у гигантов поиска нет возможностей обеспечить всеобъемлющий процесс сканирования. Поэтому каждая компания предлагает роботам уникальные математические формулы, повинуясь которым бот и выбирает страницу для посещения на следующем шаге. Это, вкупе с алгоритмами ранжирования, является одним из важнейших критериев по которым пользователи выбирают поисковую систему: где информация о сайтах более полная, свежая и полезная.
Робот-поисковик может не узнать о вашем сайте, если на него не ведут ссылки (что возможно редко - сегодня уже после регистрации доменного имени упоминания о нем обнаруживаются в сети). Если же ссылок нет, необходимо рассказать о нем поисковой системе. Для этого, как правило, используются «личные кабинеты» веб-мастеров.

Какая главная задача поисковых роботов
Как бы нам ни хотелось, но главная задача поискового робота состоит совсем не в том, чтобы рассказать миру о существовании нашего сайта. Сформулировать ее сложно, но все же, исходя из того, что поисковые системы работают лишь благодаря своим клиентам, то есть пользователям, робот должен обеспечить оперативный поиск и индексацию размещенных в сети данных . Только это позволяет ПС удовлетворить потребность аудитории в актуальной и релевантной запросам выдаче.
Конечно, роботы не могут проиндексировать 100% веб-сайтов. Согласно исследованиям, количество загруженных лидерами поиска страниц не превышает 70% от общего числа URL, размещенных в интернете. Однако то, насколько полно ваш ресурс изучен ботом, повлияет и на количество пользователей, перешедших по запросам из поиска. Поэтому и мучаются оптимизаторы в попытках «прикормить» робота, чтобы как можно быстрее знакомить его с изменениями.

В Рунете Яндекс лишь в 2016 году подвинулся на вторую строчку по охвату месячной аудитории, уступив Google. Поэтому не удивительно, что у него наибольшее количество пауков, изучающих пространство, среди отечественных ПС. Перечислять их полный список бессмысленно: его можно увидеть в разделе «Помощь вебмастеру» > Управление поисковым роботом > Как проверить, что робот принадлежит Яндексу.
Все краулеры поисковика обладают строго регламентированным user-agent. Среди тех, с которыми обязательно придется встретиться сайтостроителю:
- Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - основной индексирующий бот;
- Mozilla/5.0 (iPhone; CPU iPhone OS 8_1 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B411 Safari/600.1.4 (compatible; YandexBot/3.0; +http://yandex.com/bots) - индексирующий паук;
- Mozilla/5.0 (compatible; YandexImages/3.0; +http://yandex.com/bots) - бот Яндекс.Картинок;
- Mozilla/5.0 (compatible; YandexMedia/3.0; +http://yandex.com/bots) - индексирует мультимедийные материалы;
- Mozilla/5.0 (compatible; YandexFavicons/1.0; +http://yandex.com/bots) - индексирует иконки сайтов.
Чтобы привлечь на свой сайт пауков Яндекса, рекомендуется выполнить несколько простых действий:
- правильно настроить robots.txt;
- создать RSS-фид;
- разместить sitemap с полным списком индексируемых страниц;
- создать страницу (или страницы), которые будут содержать ссылки на все документы ресурса;
- настроить HTTP-статусы;
- обеспечить социальную активность после публикации материалов (причем не только комментарии, а расшаривание документа);
- интенсивное размещение новых уникальных текстов.
В пользу последнего аргумента говорит способность ботов запоминать скорость обновления контента и приходить на сайт с обнаруженной периодичностью добавления новых материалов.
Если же вы хотели бы запретить доступ краулерам Яндекса к страницам (например, к техническим разделам), требуется настроить файл robots.txt. Пауки ПС способны понимать стандарт исключений для ботов, поэтому сложностей при создании файла обычно не появляется.
User-agent: Yandex
Disallow: /
запретит ПС индексировать весь сайт.
Кроме того, роботы Яндекса умеют учитывать рекомендации, указанные в мета-тегах. Пример: запретит демонстрацию в выдаче ссылки на копию документа из архива. А добавление в код страницы тега укажет на то, что данный документ не нужно индексировать.
Полный список допустимых значений можно найти в разделе «Использование HTML-элементов» Помощи вебмастеру.

Роботы поисковики Google
Основной механизм индексации контента WWW у Google носит название Googlebot. Его механизм настроен так, чтобы ежедневно изучать миллиарды страниц с целью поиска новых или измененных документов. При этом бот сам определяет, какие страницы сканировать, а какие - игнорировать.
Для этого краулера важное значение имеет наличие на сайте файла Sitemap, предоставляемого владельцем ресурса. Сеть компьютеров, обеспечивающая его функционирование настолько мощна, что бот может делать запросы к страницам вашего сайта раз в пару секунд. А настроен бот так, чтобы за один заход проанализировать большее количество страниц, чтобы не вызывать нагрузку на сервер. Если работа сайта замедляется от частых запросов паука, скорость сканирования можно изменить, настроив в Search Console. При этом повысить скорость сканирования, к сожалению, нельзя.
Бота Google можно попросить повторно просканировать сайт. Для этого необходимо открыть Search Console и найти функцию Добавить в индекс, которая доступна пользователям инструмента Просмотреть как Googlebot. После сканирования появится кнопка Добавить в индекс. При этом Google не гарантирует индексацию всех изменений, поскольку процесс связан с работой «сложных алгоритмов».
Полезные инструменты
Перечислить все инструменты, которые помогают оптимизаторам работать с ботами, достаточно сложно, поскольку их масса. Кроме упомянутого выше «Посмотреть как Googlebot», стоит отметить анализаторы файлов robots.txt Google и Яндекса, анализаторы файлов Sitemap, сервис «Проверка ответа сервера» от российской ПС. Благодаря их возможностям, вы будете представлять, как выглядит ваш сайт в глазах паука, что поможет избежать ошибок и обеспечить наиболее быстрое сканирование сайта.
Вопреки расхожему мнению, робот непосредственно не занимается какой-либо обработкой сканируемых документов. Он их только считывает и сохраняет, дальше их обработку осуществляют другие программы. Наглядное подтверждение можно получить, анализируя логи сайта, который индексируется в первый раз. При первом визите бот сначала запрашивает файл robots.txt, затем главную страницу сайта. То есть идет по единственной известной ему ссылке. На этом первый визит бота всегда и заканчивается. Через некоторое время (обычно на следующий день) бот запрашивает следующие страницы - по ссылкам, которые найдены на уже считанной странице. Дальше процесс продолжается в том же порядке: запрос страниц, ссылки на которые уже найдены - пауза на обработку считанных документов - следующий сеанс с запросом найденных ссылок.
Разбор страниц «на лету» означал бы значительно бо льшую ресурсоемкость робота и потери времени. Каждый сервер сканирования запускает множество процессов-ботов параллельно. Они должны действовать максимально быстро, чтобы успеть считывать новые страницы и повторно перечитывать уже известные. Поэтому боты только считывают и сохраняют документы. Все, что они сохраняют, ставится в очередь на обработку (разборку кода). Найденные при обработке страниц ссылки ставятся в очередь заданий для ботов. Так и идет непрерывное сканирование всей сети. Единственное, что бот может и должен анализировать «на лету» - это файл robots.txt, чтобы не запрашивать адреса, которые в нем запрещены. При каждом сеансе сканирования сайта робот в первую очередь запрашивает этот файл, а уже после него - все стоящие в очереди на сканирование страницы.
Виды поисковых роботов
У каждой поисковой системы есть свой набор роботов для различных целей.
В основном они различаются по функциональному назначению, хотя границы очень условны, и каждый поисковик понимает их по-своему. Системам только для полнотекстового поиска вполне достаточно одного робота на все случаи жизни. У тех поисковиков, которые заняты не только текстом, боты разделяются как минимум на две категории: для текстов и рисунков. Существуют также отдельные боты, занятые специфическими видами контента - мобильным, блоговым, новостным, видео и т.д.
Роботы Google
Все роботы Google носят общее название Googlebot. Основной робот-индексатор «представляется» так:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Этот бот занят сканированием HTML -страниц и прочих документов для основного поиска Google. Он же изредка считывает файлы CSS и JS - в основном это можно заметить на ранней стадии индексирования сайта, пока бот обходит сайт впервые. Принимаемые типы контента - все (Accept: */*).
Второй из основных ботов занят сканированием изображений с сайта. Он «представляется» просто:
Googlebot-Image/1.0
Еще в логах замечены как минимум три бота, занятых сбором контента для мобильной версии поиска. Поле User-agent всех трех оканчивается строкой:
(compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)
Перед этой строкой - модель мобильного телефона, с которой этот бот совместим. У замеченных ботов это модели телефонов Nokia, Samsung и iPhone. Принимаемые типы контента - все, но с указанием приоритетов:
Accept: application/vnd.wap.xhtml+xml,application/xhtml+xml;q=0.9,text/vnd.wap.wml;q=0.8,text/html;q=0.7,*/*;q=0.6
Роботы Яндекса
Из поисковиков, активно действующих в Рунете, самая большая коллекция ботов у Яндекса. В разделе помощи для вебмастеров можно найти официальный список всего паучьего личного состава. Приводить его здесь полностью нет смысла, поскольку в этом списке периодически происходят изменения.
Тем не менее, о самых важных для нас роботах Яндекса нужно упомянуть отдельно.
Основной индексирующий робот
на текущий момент зовется
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)
Ранее представлялся как
Yandex/1.01.001 (compatible; Win16; I)
Считывает HTML -страницы сайта и другие документы для индексирования. Список принимаемых медиатипов ранее был ограничен:
Accept: text/html, application/pdf;q=0.1, application/rtf;q=0.1, text/rtf;q=0.1, application/msword;q=0.1, application/x-shockwave-flash;q=0.1, application/vnd.ms-excel;q=0.1, application/vnd.ms-powerpoint;q=0.1
С 31 июля 2009 года в этом списке было замечено существенное расширение (число типов почти удвоилось), а с 10 ноября 2009 года список укоротился до */* (все типы).
Этого робота живо интересует вполне определенный набор языков: русский, несколько менее украинский и белорусский, еще чуть меньше английский и совсем мало - все остальные языки.
Accept-Language: ru, uk;q=0.8, be;q=0.8, en;q=0.7, *;q=0.01
Робот-сканер изображений несет в поле User-agent строку:
Mozilla/5.0 (compatible; YandexImages/3.0; +http://yandex.com/bots)
Занимается сканированием графики разных форматов для поиска в картинках.
В отличие от Google, у Яндекса есть отдельные боты для обслуживания некоторых специальных функций общего поиска.
Робот-«зеркальщик»
Mozilla/5.0 (compatible; YandexBot/3.0; MirrorDetector; +http://yandex.com/bots)
Ничего особенно сложного не делает - периодически появляется и проверяет, совпадает ли главная страница сайта при обращении к домену с www. и без. Также проверяет параллельные домены-«зеркала» на совпадение. По-видимому, зеркалами и канонической формой доменов в Яндексе занимается отдельный программный комплекс, не связанный напрямую с индексированием. Иначе решительно нечем объяснить существование для этой цели отдельного бота.
Сборщик иконок favicon.ico
Mozilla/5.0 (compatible; YandexFavicons/1.0; +http://yandex.com/bots)
Периодически появляется и запрашивает иконку favicon.ico, которая потом появляется в поисковой выдаче рядом со ссылкой на сайт. По каким причинам эту обязанность не совмещает сборщик картинок, неизвестно. По-видимому, также имеет место отдельный программный комплекс.
Проверочный бот для новых сайтов, работает при добавлении в форму AddURL
Mozilla/5.0 (compatible; YandexWebmaster/2.0; +http://yandex.com/bots)
Этот бот проверяет отклик сайта, посылая запрос HEAD к корневому URL . Таким образом проверяется существование главной страницы в домене и анализируются HTTP -заголовки этой страницы. Также бот запрашивает файл robots.txt в корне сайта. Таким образом после подачи ссылки в AddURL определяется, что сайт существует и ни в robots.txt, ни в HTTP -заголовках не запрещен доступ к главной странице.
Робот Рамблера
В настоящее время уже не работает
, поскольку Рамблер сейчас использует поиск Яндекса
Робота-индексатора Рамблера легко опознать в логах по полю User-agent
StackRambler/2.0 (MSIE incompatible)
По сравнению с «коллегами» из других поисковых систем этот бот кажется совсем простым: не указывает список медиатипов (соответственно, получает запрошенный документ любого типа), поле Accept-Language в запросе отсутствует, в запросах бота не встречено также поле If-Modified-since.
Робот Mail.Ru
Об этом роботе пока известно немного. Разработку собственного поиска портал Mail.Ru ведет уже давно, но все никак не соберется этот поиск запустить. Поэтому достоверно известно только наименование бота в User-agent - Mail.Ru/2.0 (ранее - Mail.Ru/1.0). Наименование бота для директив файла robors.txt нигде не публиковалось, есть предположение, что бота так и следует звать Mail.Ru.
Прочие роботы
Поиск в интернете, конечно, не ограничивается двумя поисковыми системами. Поэтому существуют и другие роботы - например робот Bing - поисковой системы от Microsoft и другие роботы. Так, в частности, в Китае есть национальная поисковая система Baidu - но ее робот вряд ли долетит до середины реки дойдет до русского сайта .
Кроме того, в последнее время расплодилось много сервисов - в частности solomono - которые хоть и не являются поисковыми системами, но тоже сканирует сайты. Часто ценность передачи информации о сайте таким системам сомнительна, и поэтому их роботов можно запретить в
Поисковым роботом называется специальная программа какой-либо поисковой системы, которая предназначена для занесения в базу (индексирования) найденных в Интернете сайтов и их страниц. Также используются названия: краулер, паук, бот, automaticindexer, ant, webcrawler, bot, webscutter, webrobots, webspider.
Принцип работы
Поисковый робот — это программа браузерного типа. Он постоянно сканирует сеть: посещает проиндексированные (уже известные ему) сайты, переходит по ссылкам с них и находит новые ресурсы. При обнаружении нового ресурса робот процедур добавляет его в индекс поисковика. Поисковый робот также индексирует обновления на сайтах, периодичность которых фиксируется. Например, обновляемый раз в неделю сайт будет посещаться пауком с этой частотой, а контент на новостных сайтах может попасть в индекс уже через несколько минут после публикации. Если на сайт не ведет ни одна ссылка с других ресурсов, то для привлечения поисковых роботов ресурс необходимо добавить через специальную форму (Центр вебмастеров Google, панель вебмастера Яндекс и т.д.).
Виды поисковых роботов
Пауки Яндекса :
- Yandex/1.01.001 I — основной бот, занимающийся индексацией,
- Yandex/1.01.001 (P) — индексирует картинки,
- Yandex/1.01.001 (H) — находит зеркала сайтов,
- Yandex/1.03.003 (D) — определяет, соответствует ли страница, добавленная из панели вебмастера, параметрам индексации,
- YaDirectBot/1.0 (I) — индексирует ресурсы из рекламной сети Яндекса,
- Yandex/1.02.000 (F) — индексирует фавиконы сайтов.
Пауки Google:
- Робот Googlebot — основной робот,
- Googlebot News — сканирует и индексирует новости,
- Google Mobile — индексирует сайты для мобильных устройств,
- Googlebot Images — ищет и индексирует изображения,
- Googlebot Video — индексирует видео,
- Google AdsBot — проверяет качество целевой страницы,
- Google Mobile AdSense и Google AdSense — индексирует сайты рекламной сети Google.
Другие поисковики также используют роботов нескольких видов, функционально схожих с перечисленными.
Похожие статьи
 Система BBR: регулирование заторов непосредственно по заторам
Система BBR: регулирование заторов непосредственно по заторам
 Как на смартфонах Meizu сделать Hard Reset — сброс настроек до заводских Забыл графический ключ meizu mx5
Как на смартфонах Meizu сделать Hard Reset — сброс настроек до заводских Забыл графический ключ meizu mx5
 Планшет Acer iconia W510 не видит флешку в биосе
Планшет Acer iconia W510 не видит флешку в биосе
 Тарифы и услуги мтс в крыму
Тарифы и услуги мтс в крыму
 Майнинг на видеокарте AMD Radeon Vega — производительность, технические характеристики Сравнение с конкурентами
Майнинг на видеокарте AMD Radeon Vega — производительность, технические характеристики Сравнение с конкурентами
 Неубиваемые смарт и телефон
Неубиваемые смарт и телефон
 Взаимодействие браузера и сервера на примере GET и POST запросов
Взаимодействие браузера и сервера на примере GET и POST запросов Подключение смартфона HTC к компьютеру
Подключение смартфона HTC к компьютеру Алфавитный подход к измерению информации
Алфавитный подход к измерению информации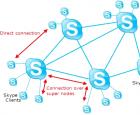 Смотреть что такое "VoIP" в других словарях Связь ip телефония
Смотреть что такое "VoIP" в других словарях Связь ip телефония